# 机器学习
# 概念
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它通过专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,还凭借重新组织已有的知识结构来不断改善自身的性能。
近十年来人工智能越来越热门,在我们的日常学习中,我们经常听到一大堆专有名词,像人工智能,机器学习,监督学习,非监督学习,深度学习,强化学习这些, 那它们之间存在什么样的关系呢?
其中,强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
目标:解决预测和分类等问题。
# 机器学习方法
机器学习实际上包含很多数学方法,会涉及到统计学、概率论、信息论等知识。 目标是:利用已知的数据,创建一个数学模型,并最终利用该模型进行预测。
如上图,采用大量历史(训练)数据进行训练, 获取到一个经验推理模型。预测就是应用训练出来的模型,来解决一个未知的问题。
数据是否有效,关系到训练最终的模型质量。
训练方法是否有效,同样关系到训练最终的模型质量。
# 机器学习的步骤
1. 确定与问题相关的数据(明确输入和输出、均为可观测数据)
2. 收集数据、并预处理(数据准备,适用于学习和训练的形式)
3. 分析预测结果的类型(分类,回归 à 是预测温度值,还是判断属于某类)
4. 根据预测结果的类型,找到输入和输出之间的逻辑关系(黑盒),确定合适的模型或算法。
5. 用这个算法(模型)去解决新的问题(未知数据 à 同类问题预测)
# 机器学习的常用术语
特征(feature)à 模型的输入 à 比拟函数中的自变量
标记(label) à 模型的期望输出(非预测值)à 比拟函数中的因变量
例如,最简单的线性方程预测模型:f (x) = mx + b ,其中 x 是特征 **(feature, 自变量),是函数(模型)的输入数据,f (x) 是预测输出的结果(因变量),其目标是尽量与 ** 标记值 y 相同或相近。
我们的目标就是获取 f (x) 的具体形式,也就是模型中的参数 m 和 b。例如:农业中的测产,不同情况的变量,造成农作物的产量和品质的变化。其目标是学习规律,进行调控。
# 分类和回归
机器学习的主要任务便是聚焦于两个问题:分类和回归。
回归问题: regression, 数据通常是连续的。
● 根据车的品牌,车龄,型号,预测车的价值
● 根据每天卡路里摄入以及运动量,预测一周后的体重
● 基于树的直径,预测树的年龄
分类问题:classification, 数据结果往往是离散的
● 根据影像学资料,判断是否患有某种疾病
● 根据 email 内容,判断是否为垃圾邮件
# 注意事项
- 训练模型的输入输出,就是自变量和因变量, 对应 feature 和 predict(理想状况下 predict==label)。
- 训练和测试的数据集必须是规范,格式统一的,方便计算机处理。
- 分类的数目必须是有限个。例如,最常见的二分类问题。属于定性问题。
回归问题,目标是寻找最优拟合的连续曲线,属于定量问题。
- 训练的核心就是从数据的 feature 和 label 间寻找联系,可能有无数种的算法(模型), 每种算法都有自己的优缺点(根据场景选择合适的)。
- 根据预测(predict)的情况,我们可能需要重新调整算法和模型(炼丹师)。
# 环境安装
任务:搭建 python 环境,安装神经网络框架(平台工具)以及要使用的功能模块库等等。
# 安装 Conda 虚拟环境
1. Anaconda 的安装:https://www.anaconda.com/,完成后在 “Anaconda prompt” 中,采用命令行去创建虚拟环境。
2. 创建虚拟环境
conda create -n py38 python=3.8 |
3. 然后激活当前环境
conda activate py38 |
4. 查看当前虚拟环境中已安装内容
conda list |
查看当前已有的虚拟环境
conda env list
# pip 更换国内镜像
1. 方法一、临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package 包名 |
- windows 下 pip 更换国内源的方法
打开我的电脑,在地址栏中输入 % APPDATA% 按回车跳转到目标目录。在目录下创建一个 pip 文件夹,并在其中创建一个 pip.ini 文件。输入以下信息(不用 window 自带的记事本,建议采 notepad++)
文件内容为:
[global] | |
timeout = 6000 | |
index-url = https://mirrors.aliyun.com/pypi/simple/ | |
trusted-host = mirrors.aliyun.come |
# 安装神经网络框架(平台)
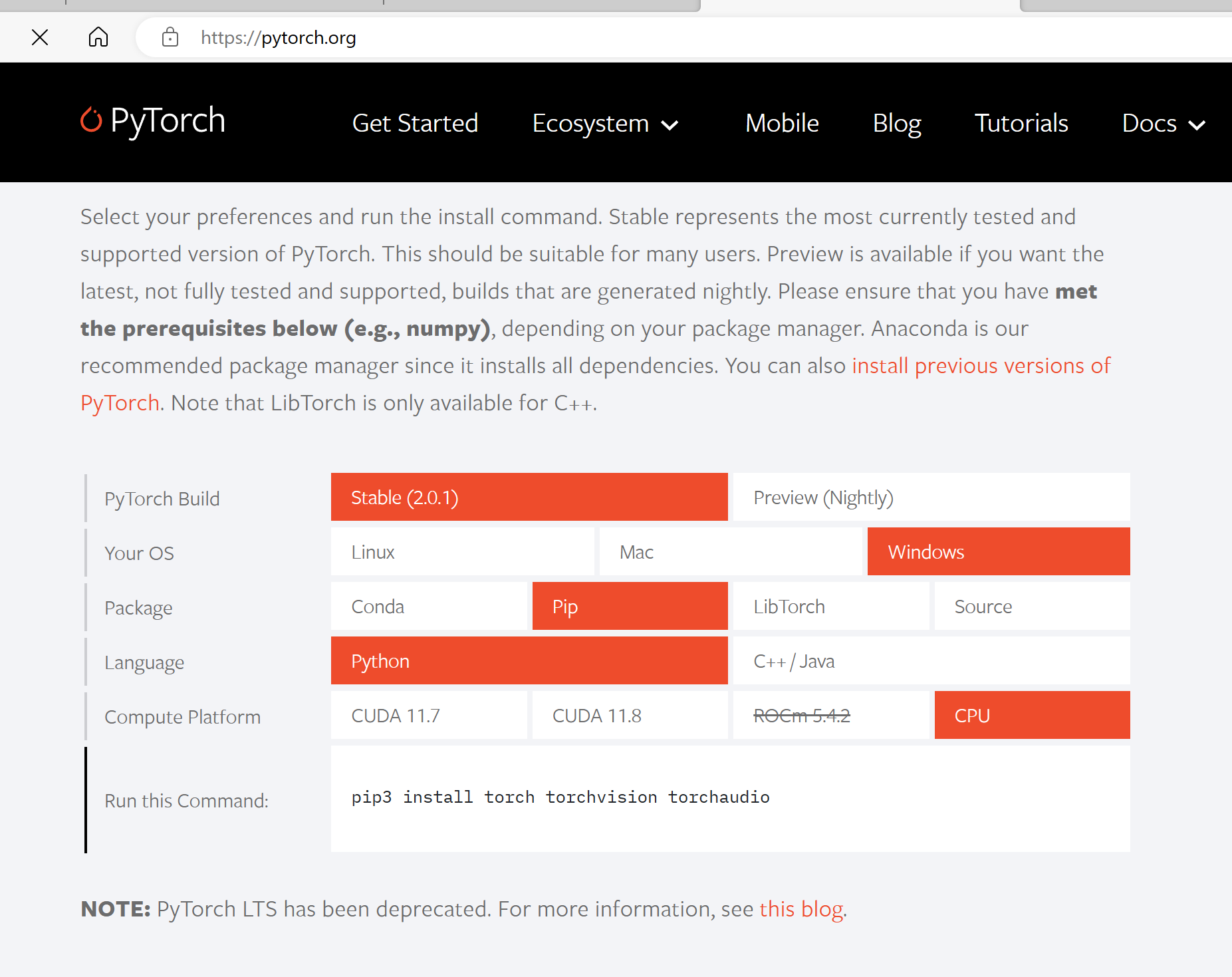
访问 PyTorch 的官网 PyTorch.org 按照官网提示选择对应的版本进行安装。
需注意的是:如果你的电脑支持 CUDA 并且显存大于 2G,可以安装 CUDA 版本,在神经网络的训练过程中效率会高一点。安装 Cuda 驱动的版本是 cuda11, 所以上面选择的也是 11。
如果电脑显卡不支持 cuda, 那还可以安装 CPU 版本
# 安装 jupyter notebook
Jupyter Notebook 是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档,支持实时代码,数学方程,可视化和 markdown。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等
即 Jupyter Notebook 中所有交互计算、编写说明文档、数学公式、图片以及其他富媒体形式的输入和输出,都是以文档的形式体现的。这些文档是保存为后缀名为 **.ipynb** 的 JSON 格式文件,不仅便于版本控制,也方便与他人共享。此外,文档还可以导出为:HTML、LaTeX、PDF 等格式。
下面的命令用于安装 jupyter notebook:
pip install jupyter | |
pip install --upgrade notebook==6.4.12 |
安装 jupyter notebook 的提示功能
pip install jupyter_contrib_nbextensions | |
jupyter contrib nbextension install --user | |
pip install --user jupyter_nbextensions_configurator | |
jupyter nbextensions_configurator enable --user |
启动 jupyter
jupyter notebook |